#Graph Database Market
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr office adopted Tommy, an 11-year-old Pomeranian.
Link
2 notes
·
View notes
Text
Graph Database Market Size, Share, Analysis, Forecast & Growth 2032: Investment Trends and Funding Landscape
The Graph Database Market size was valued at US$ 2.8 billion in 2023 and is expected to reach US$ 15.94 billion in 2032 with a growing CAGR of 21.32 % over the forecast period 2024-2032.
Graph Database Market is rapidly transforming the data management landscape by offering a highly efficient way to handle complex, connected data. With the ever-growing need for real-time insights and deep relationship mapping, businesses across sectors such as healthcare, finance, telecom, and retail are increasingly adopting graph databases to drive smarter, faster decision-making.
Graph Database Market is gaining strong momentum as organizations shift from traditional relational databases to graph-based structures to address modern data challenges. The rising importance of AI, machine learning, and big data analytics is fueling the need for more flexible, scalable, and intuitive data systems—an area where graph databases excel due to their ability to uncover intricate patterns and connections with low latency and high performance.
Get Sample Copy of This Report: https://www.snsinsider.com/sample-request/3615
Market Keyplayers:
Oracle Corporation
Ontotext
Orient DB
Hewlett Packard Enterprise
Microsoft Corporation
Teradata Corporation
Stardog Union Inc.
Amazon Web Services, Inc.
Objectivity Inc.
MangoDB
TIBCO Software
Franz Inc.
TigerGraph Inc.
DataStax
IBM Corporation
Blazegraph
Openlink Software
MarkLogic Corporation
Market Analysis
The evolution of data complexity has made traditional relational databases insufficient for many modern applications. Graph databases, by storing data as nodes and edges, simplify complex relationships and enable dynamic querying across connected datasets. This makes them particularly valuable for fraud detection, recommendation engines, knowledge graphs, social network analysis, and enterprise data management.
Graph database technology is being integrated with cloud platforms and advanced analytics solutions, further expanding its appeal. Startups and tech giants alike are investing in graph-based innovations, driving ecosystem growth and enhancing capabilities. Moreover, open-source projects and graph query languages like Cypher and Gremlin are contributing to the market’s technical maturity and adoption.
Market Trends
Rising adoption in fraud detection and cybersecurity analytics
Increased demand for real-time recommendation systems
Integration with AI and machine learning for advanced pattern recognition
Emergence of hybrid and multi-model database systems
Expansion of graph capabilities in cloud-native environments
Growing use of knowledge graphs in enterprise search and NLP
Surge in funding and acquisitions among graph database vendors
Adoption in government and public sector for intelligence operations
Market Scope
The graph database market encompasses a wide array of industries where connected data is critical. From telecommunications optimizing network infrastructures to healthcare improving patient outcomes through connected health records, the applications are diverse and expanding. As digital transformation accelerates, the need for intuitive, flexible data platforms is pushing enterprises to explore graph database technologies. Vendors are offering customized solutions for SMEs and large-scale deployments alike, with support for multiple data models and integration capabilities.
In addition to industry adoption, the market scope is defined by advancements in technology that allow for greater scalability, security, and usability. Developers are increasingly favoring graph databases for projects that involve hierarchical or network-based data. Education around graph data models and improvements in visualization tools are making these systems more accessible to non-technical users, broadening the market reach.
Market Forecast
The graph database market is poised for substantial long-term growth, driven by escalating demands for real-time data processing and intelligent data linkage. As organizations prioritize digital innovation, the role of graph databases will become even more central in enabling insights from interconnected data. Continuous developments in artificial intelligence, cloud computing, and big data ecosystems will further amplify market opportunities. Future adoption is expected to flourish not just in North America and Europe, but also in emerging economies where digital infrastructure is rapidly maturing.
Investments in R&D, increasing partnerships among technology providers, and the emergence of specialized use cases in sectors such as legal tech, logistics, and social media analysis are indicators of a thriving market. As businesses seek to gain competitive advantages through smarter data management, the adoption of graph databases is set to surge, ushering in a new era of contextual intelligence and connectivity.
Access Complete Report: https://www.snsinsider.com/reports/graph-database-market-3615
Conclusion
In an age where understanding relationships between data points is more critical than ever, graph databases are redefining how businesses store, query, and derive value from data. Their ability to model and navigate complex interdependencies offers a strategic edge in a data-saturated world. As innovation accelerates and digital ecosystems become increasingly interconnected, the graph database market is not just growing—it is reshaping the very foundation of data-driven decision-making. Organizations that recognize and embrace this shift early will be best positioned to lead in tomorrow’s connected economy.
About Us:
SNS Insider is one of the leading market research and consulting agencies that dominates the market research industry globally. Our company's aim is to give clients the knowledge they require in order to function in changing circumstances. In order to give you current, accurate market data, consumer insights, and opinions so that you can make decisions with confidence, we employ a variety of techniques, including surveys, video talks, and focus groups around the world.
Contact Us:
Jagney Dave - Vice President of Client Engagement
Phone: +1-315 636 4242 (US) | +44- 20 3290 5010 (UK)
0 notes
Text
Graph Database Market Dynamics, Trends, and Growth Factors 2032
The Graph Database Market size was valued at US$ 2.8 billion in 2023 and is expected to reach US$ 15.94 billion in 2032 with a growing CAGR of 21.32 % over the forecast period 2024-2032
Graph Database Market is experiencing exponential growth due to the rising need for handling complex and interconnected data. Businesses across various industries are leveraging graph databases to enhance data relationships, improve decision-making, and gain deeper insights. The adoption of AI, machine learning, and real-time analytics is further driving demand for graph-based data management solutions.
Graph Database Market continues to evolve as organizations seek efficient ways to manage highly connected data structures. Unlike traditional relational databases, graph databases provide superior performance in handling relationships between data points. The surge in big data, social media analytics, fraud detection, and recommendation engines is fueling widespread adoption across industries such as finance, healthcare, e-commerce, and telecommunications.
Get Sample Copy of This Report: https://www.snsinsider.com/sample-request/3615
Market Keyplayers:
Oracle Corporation
Ontotext
Orient DB
Hewlett Packard Enterprise
Microsoft Corporation
Teradata Corporation
Stardog Union Inc.
Amazon Web Services
Market Trends Driving Growth
1. Rising Demand for AI and Machine Learning Integration
Graph databases play a crucial role in AI and machine learning by enabling more accurate predictions, knowledge graphs, and advanced data analytics. Businesses are integrating graph technology to enhance recommendation systems, cybersecurity, and fraud prevention.
2. Increased Adoption in Fraud Detection and Risk Management
Financial institutions and e-commerce platforms are utilizing graph databases to detect fraudulent transactions in real time. By mapping and analyzing relationships between entities, these databases can uncover hidden patterns that indicate suspicious activities.
3. Growth of Personalized Recommendation Engines
Tech giants like Amazon, Netflix, and Spotify rely on graph databases to power their recommendation engines. By analyzing user behavior and interconnections, companies can deliver highly personalized experiences that enhance customer satisfaction.
4. Expansion in Healthcare and Life Sciences
Graph databases are revolutionizing healthcare by mapping patient records, drug interactions, and genomic data. Researchers and healthcare providers can leverage these databases to improve diagnostics, drug discovery, and personalized medicine.
5. Surge in Knowledge Graph Applications
Enterprises are increasingly using knowledge graphs to organize and retrieve vast amounts of unstructured data. This trend is particularly beneficial for search engines, virtual assistants, and enterprise data management systems.
Enquiry of This Report: https://www.snsinsider.com/enquiry/3615
Market Segmentation:
By Component
Software
Services
By Deployment
Cloud
On-Premise
By Type
Relational (SQL)
Non-Relational (NoSQL)
By Application
Identity and Access Management
Customer Analytics
Recommendation Engine
Master Data Management
Privacy and Risk Compliance
Fraud Detection and Risk Management
Others
By Analysis Type
Community Analysis
Connectivity Analysis
Centrality Analysis
Path Analysis
Market Analysis and Growth Projections
The shift towards real-time data analytics and the increasing complexity of enterprise data management are key growth drivers. Leading database providers such as Neo4j, Amazon Neptune, and TigerGraph are investing in scalable and high-performance solutions to cater to growing demand.
Key industries driving adoption include:
Banking and Finance: Graph databases enhance fraud detection, risk analysis, and regulatory compliance.
Healthcare and Biotech: Used for genomic sequencing, drug discovery, and personalized treatment plans.
Retail and E-commerce: Enhancing customer engagement through personalized recommendations.
Cybersecurity: Detecting anomalies and cyber threats through advanced network analysis.
Despite its rapid growth, the market faces challenges such as data privacy concerns, high implementation costs, and the need for specialized skills. However, continuous advancements in cloud computing and database-as-a-service (DBaaS) solutions are helping businesses overcome these barriers.
Regional Analysis
1. North America Leading the Market
North America dominates the graph database market, driven by the presence of major tech companies, financial institutions, and government initiatives in AI and big data analytics. The U.S. and Canada are investing heavily in advanced data infrastructure.
2. Europe Experiencing Steady Growth
Europe is witnessing strong adoption, particularly in industries like healthcare, finance, and government sectors. Regulations such as GDPR are pushing organizations to adopt more efficient data management solutions.
3. Asia-Pacific Emerging as a High-Growth Region
Asia-Pacific is experiencing rapid growth due to increased digital transformation in China, India, and Japan. The rise of e-commerce, AI-driven applications, and cloud adoption are key factors driving demand.
4. Latin America and Middle East & Africa Showing Potential
Although these regions have a smaller market share, there is growing interest in graph databases for financial security, telecommunications, and government data management initiatives.
Key Factors Fueling Market Growth
Rising Complexity of Data Relationships: Traditional relational databases struggle with highly connected data structures, making graph databases the preferred solution.
Cloud-Based Deployments: The availability of cloud-native graph database solutions is making adoption easier for businesses of all sizes.
Real-Time Analytics Demand: Businesses require instant insights to improve decision-making, fraud detection, and customer interactions.
AI and IoT Expansion: The growing use of AI and Internet of Things (IoT) is creating a surge in data complexity, making graph databases essential for real-time processing.
Open-Source Innovation: Open-source graph database platforms are making technology more accessible and fostering community-driven advancements.
Future Prospects and Industry Outlook
1. Increased Adoption in Enterprise AI Solutions
As AI-driven applications continue to grow, graph databases will play a vital role in structuring and analyzing complex datasets, improving AI model accuracy.
2. Expansion of Graph Database-as-a-Service (DBaaS)
Cloud providers are offering graph databases as a service, reducing infrastructure costs and simplifying deployment for businesses.
3. Integration with Blockchain Technology
Graph databases are being explored for blockchain applications, enhancing security, transparency, and transaction analysis in decentralized systems.
4. Enhanced Cybersecurity Applications
As cyber threats evolve, graph databases will become increasingly critical in threat detection, analyzing attack patterns, and strengthening digital security frameworks.
5. Growth in Autonomous Data Management
With advancements in AI-driven automation, graph databases will play a central role in self-learning, adaptive data management solutions for enterprises.
Access Complete Report:https://www.snsinsider.com/reports/graph-database-market-3615
Conclusion
The Graph Database Market is on a high-growth trajectory, driven by its ability to handle complex, interconnected data with speed and efficiency. As industries continue to embrace AI, big data, and cloud computing, the demand for graph databases will only accelerate. Businesses investing in graph technology will gain a competitive edge in data-driven decision-making, security, and customer experience. With ongoing innovations and increasing enterprise adoption, the market is poised for long-term expansion and transformation.
About Us:
SNS Insider is one of the leading market research and consulting agencies that dominates the market research industry globally. Our company's aim is to give clients the knowledge they require in order to function in changing circumstances. In order to give you current, accurate market data, consumer insights, and opinions so that you can make decisions with confidence, we employ a variety of techniques, including surveys, video talks, and focus groups around the world.
Contact Us:
Jagney Dave - Vice President of Client Engagement
Phone: +1-315 636 4242 (US) | +44- 20 3290 5010 (UK)
#Graph Database Market#Graph Database Market Analysis#Graph Database Market Scope#Graph Database Market Share#Graph Database Market Trends
0 notes
Text
Graph Database Market: How Businesses Are Transforming Data Analysis
0 notes
Text

#Graph Database Market#Graph Database Market Share#Graph Database Market Size#Graph Database Market Research#Graph Database Industry#What is Graph Database?
0 notes
Text
Graph Database Market - Forecast(2024 - 2030)
Overview
The Graph Database Market is forecast to reach $ 3.21 billion by 2025 growing at a CAGR of 22.6% during the forecast period 2020-2025. The Growth of Graph Database Market can be attributed to the increase in application areas of graph database, upsurge in penetration of connected data to optimize marketing performance, surge in adoption of graph database software in the healthcare sector, rise in need for better response time & accuracy to discover new data correlations etc. Rising adoption of cloud based solutions to enhance business processes will further fuel the growth of Graph Database Market. Increase in usage of virtualization in big data analytics and technological advancements in graph database are expected to create lucrative opportunities for the market during the forecast period.
Request Sample
Key Takeaways
Large enterprises to boost the adoption of graph database tools as the implementation of these tools and services in large enterprises simplifies risk and compliance management tasks.
As most of the organizations has digitalized their businesses, the supply chain management application is expected to grow at the highest CAGR due to rising need for real-time, location-based insights across the entire supply chain.
Growing dependency on connected data for fraud detection across various industries including e-commerce, banking, financial services and insurance, contributes to the growth of global graph database market.
The transportation & logistic industry is expected to witness the highest CAGR in the graph database market during the forecast period, due to the rising adoption of graph database technology in this industry to compute fast, to enable localized door-to-door delivery of goods between buyers & sellers, and to scale their business to include the supply chain.
Implementation challenges and lack of technical expertise to create hurdles for the Graph Database Market.
Component Type - Segment Analysis
The software segment has been analyzed to attribute to the majority of share in the Graph Database Market during the forecast period 2020-2025 owing to the rising demand for software, as massive volume of data is continuously generated due to which managing data using a traditional relational database infrastructure is difficult for enterprises. These organizations need to manage their data efficiently and effectively to enhance their productivity and maintain business continuity. The proliferation of data amounting to big data has forced vendors to design graph database software and help Information Technology (IT) teams simplify and manage their decision-making process. For Instance, in July 2019 Dgraph raised $11.5 million for scalable graph database solutions. Thus Graph database tools are becoming prevalent among data-sensitive organizations to cope with the ever-increasing volumes of data which is indicating opportunity for the growth of Graph Database Market.
Inquiry Before Buying
End-user - Segment Analysis
Among the end users, the healthcare and life sciences sector is expected to dominate the Graph Database Market with the highest CAGR of 12.48% during the forecast period 2020-2025. Graph database software plays a key role in the healthcare and life sciences sectors for recording patient’s information and to provide this information to numerous patients or healthcare providers. Healthcare organizations and institutions are using graph database tools to improve and enhance the operational efficiency, safety, reduce costs, and improvise the quality of patient care, thus fueling its adoption in the healthcare sector. Industry regulations, such as HIPPA and HITECH, provide guidelines for healthcare data privacy and the safe transmission of electronic health data. Healthcare-focused start-ups are leveraging the graph database technology to cater to the unmet needs of customers. For instance, Zephyr Health, a health-focused start-up is leveraging graph database technology as one important component of its service offerings. Furthermore, by using graph database technology, healthcare organizations are leveraging the connections within their existing data such as connected genome or information related to patient treatments, which is opportunistic for the graph database market.
Geography - Segment Analysis
North America dominated the graph database market accounting for 42% of shares in 2019 and this trend is expected to continue over the forecast period 2020-2025. The emergence of technology-based enterprises and industries has created the significant growth opportunities for the graph database vendors in this region as the organizations highly rely on data, which is driving the adoption of graph database tools and related technologies. Increasing number of manufacturing firms, proliferation of Internet of Things (IoT) devices, and emergence of AI will further fuel the market growth in this region. The rapid generation of data across industry verticals and the increasing investments in new technologies, such as Machine Learning (ML) is expected to propel the demand for graph database tools during the forecast period. Increasing investments by various graph database vendors in these regions will further fuel the growth of the market. For instance, in September 2019, TigerGraph a California-based software developer raised $32 million for graph database tools.
Schedule a Call
Drivers – Smart Display Market
Real-time big data mining with visualization of results to drive the Graph Database Market.
Graph database eases the distribution of any data across data centers or cloud regions, making business applications ready to scale, and able to create real-time insights and experiences. Moreover, it helps display insights through data visualizations and provides a real-time prediction for streaming data. Hence, the graph database is used to enhance business process, improve decision-making, and achieve the ability to automate, optimize, and direct decisions as per demands to reach set business goals. The growing consensus toward graph database is the most direct path to extract business decisions from the value found in the data.
Penetration of connected data to optimize marketing performance is expected to drive the Graph database Market.
Graph databases are majorly designed for highly interconnected data. It works best when the data is connected, and should be represented by how it links or refers to other data. For instance, the application of graph database technology in social network. Moreover, for highly connected data, graph database technology provides numerous benefits as compared to other relational databases, including enhanced performance, improved flexibility, and easier data modeling, which are expected to provide lucrative opportunities for the graph database market. For instance, highly connected data can cause a lot of joins, which generally are expensive. After over seven self/recursive joins, the relational database management system slows down considerably as compared to graph databases.
Challenges – Graph Database Market.
Lack of standardization and programming ease to hamper the market growth.
While graph databases are technically NoSQL databases, in practice, they cannot be implemented across a low-cost cluster, but have to run on a single machine. This is the reason behind the rapid performance degradation across a network. Another potential drawback is that developers have to write their queries using Java as there is no Standard Query Language (SQL) to retrieve data from graph databases, which means employing expensive programmers or developers use SparcQL or one of the other query languages that have been developed to support graph databases. These challenges may hinder the Graph Database Market growth.
Buy Now
Market Landscape
The Graph Database Market is dominated by major solution providers, such as IBM (US), Microsoft (US), Oracle (US), AWS (US), Neo4j (US), OrientDB (UK), TIBCO (US), Franz (US), OpenLink Software (US), MarkLogic (US), TigerGraph (US), DataStax (US), Ontotext (Bulgaria), Stardog (US), Cray (US), ArangoDB (US), Bitnine (US), Objectivity (US), Memgraph (UK), Cambridge Semantics (US), Fluree (US), and Blazegraph (US). Investments, product launches along with partnerships are the key strategies adopted by the players in the Graph Database Market
Product Launches / Collaborations / Investments
In November 2018, Neo4j raised $80 million for next-generation graph databases to grow its developer tools and support popular use cases, particularly graph-enabled artificial intelligence (AI) and machine learning (ML) systems.
In April 2019, Neo4j and Google Cloud announced a strategic partnership that will offer the Neo4j graph database delivered as a seamless experience integrated with GCP console, billing, and support services.
In July 2019, TigerGraph Launched PartnerGraph Program to Meet Growing Demand for Graph Analytics in AI and Machine Learning. New Program Enables Partners to Leverage Leading Scalable Graph Database and Analytics Platform.
#Graph Database Market#Graph Database Market Size#Graph Database Market Share#Graph Database Market Analysis#Graph Database Market Revenue#Graph Database Market Trends#Graph Database Market Growth#Graph Database Market Research#Graph Database Market Outlook#Graph Database Market Forecast
0 notes
Link
Increasing demand for systems competencies of processing low latency queries, precise real-time data mining through visualization of results, along with...
0 notes
Text
Market Intelligence: Insights into the Graph Database Industry
The global graph database market is poised for substantial growth, with projections indicating a remarkable increase in market share from US$ 1,938.0 million in 2022 to a projected US$ 9,909.3 million by 2032. These insights are based on meticulous research conducted by Future Market Insight, highlighting a robust Compound Annual Growth Rate (CAGR) progression from 16.3% (2017-2021) to 17.7% over the forecast period.
Due to the widespread adoption of graph database tools and services, some legacy database providers are making attempts to integrate graph database schemas with their existing relational database designs. Although the strategy may in theory lower expenses, in actuality it might restrict and impair the performance of database queries.
– Your Path to Wisdom: Secure Your Insights Sample : https://www.futuremarketinsights.com/reports/sample/rep-gb-4352
Key Market Trends and Drivers
The market’s growth trajectory is influenced by several key drivers and trends:
Low-Latency Query Response Services: A pressing demand for services capable of responding to low-latency queries is a prominent factor driving the graph database market forward. Businesses are seeking real-time insights and efficient data processing, fostering the adoption of graph databases.
Master Data Management: The increasing need for effective master data management solutions is propelling the demand for graph databases. These databases offer a versatile approach to organizing and managing complex relationships, making them an ideal choice for addressing master data challenges.
Emergence of Open Knowledge Networks: The rise of open knowledge networks is contributing to the market’s growth. Graph databases play a pivotal role in structuring and navigating intricate connections within these networks, enabling efficient knowledge dissemination and sharing.
Tracking Digital Assets: Businesses are experiencing a growing necessity to track digital assets such as documents, evaluations, agreements, and more. Graph databases offer an intuitive way to manage these assets and their relationships, facilitating streamlined asset tracking processes.
AI-Based Technologies and Services: The utilization of artificial intelligence-based graph database technologies and services is on the upswing. This integration enhances data analysis capabilities, allowing businesses to extract valuable insights from intricate data structures.
Regional Trends and Competition Analysis
The graph database market’s growth is not limited to a specific region. It is experiencing substantial expansion across various global regions, indicating a widespread adoption of graph database technologies. As businesses increasingly recognize the value of efficient data management and analysis, competition among key market players is intensifying.
Leading companies in the graph database market are strategically focusing on innovation, product development, and partnerships to gain a competitive edge. This dynamic landscape underscores the industry’s commitment to meeting evolving customer demands and staying at the forefront of technological advancements.
– Strategic Intelligence Awaits: Secure Your Custom Report Bridging Regional Data and Competitor Insights : https://www.futuremarketinsights.com/customization-available/rep-gb-4352
More Insights Available
Future Market Insights, in its new offering, presents an unbiased analysis of the Graph Database Market, presenting historical market data (2015-2021) and forecast statistics for the period of 2022-2032.
Graph Database: Market Segmentation
By Component:
Software
Services
By Deployment Mode:
Cloud
On-premises
By Organization Size:
Large Enterprises
Small and Medium-sized Enterprises (SMEs)
By Application:
Customer Analytics
Risk, Compliance and Reporting Management
Recommendation Engines
Fraud Detection and Prevention
Supply Chain Management
Operations Management and Asset Management
Infrastructure Management, IoT, Industry 4.0
Knowledge Management
Content Management, Data Extraction and Search
Metadata and Master Data Management
Scientific Data Management
Others
By Type:
RDF
Labeled Property Graph
By Vertical:
BFSI
Retail and eCommerce
Telecom and IT
Healthcare, Pharmaceuticals, and Life Sciences
Government and Public Sector
Manufacturing and Automotive
Media and Entertainment
Energy and Utilities
Travel and Hospitality
Transportation and Logistics
Others
By Region:
North America
Latin America
Asia Pacific
MEA
Europe
0 notes
Text
A specific piece of misinformation I'm responding to is the one originating from this headline:

(x)
spawning responses like

(x) which is... not entirely wrong
and
which is completely misunderstanding the original study - the Carbon Majors Database, CDP Carbon Majors Report 2017.
What this report absolutely does not say is "100 companies burn enough fossil fuels to produce 70% of emissions per year." It says something more like "70% of emissions since the 1988 can be traced back to extraction of fossil fuels by 100 producers." Those 100 producers include 36 state-owned companies, 7 state-owned producers, 41 public companies, and 16 private companies.
It also says that over half of industrial emissions since 1988 can be traced to just 25 producers. Of those 635 gigatons of emitted CO2, 59% come from state-owned producers, 32% from public companies, and 9% from private companies.
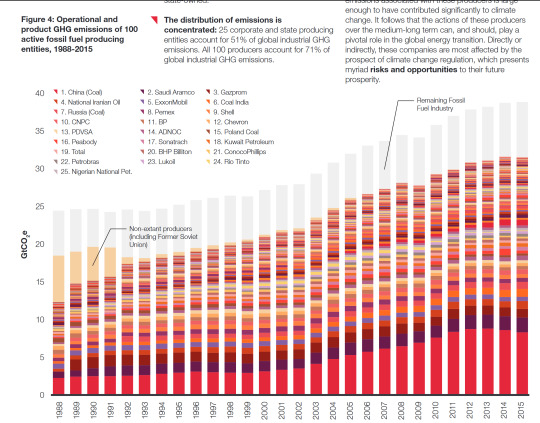
The largest shares here at the bottom of the graph are all state-owned producers: an aggregate of Chinese state-owned coal producers, Saudi Aramco (owned by the Saudi Arabian state), Gazprom (a Russian company with majority ownership by the state and partial public ownership), National Iranian Oil (unsurprisingly, nationally owned), and then finally we get to the first non-state-owned company (ExxonMobil).
The fraction is nearly identical for values for yearly emissions in 2015 - 59% of emissions since 1988 are tied to extraction by state-owned producers. Nonetheless:
"Emissions from investor-owned companies are significant: of the 30.6 GtCO2e of operational and product GHG emissions from 224 fossil fuel extraction companies, 30% is public investor-owned, 11% is private investor-owned, and 59% is state-owned."
There is absolutely immense responsibility on producers for extracting, marketing, and selling fossil fuels, and for (in several notable cases) deliberately covering up anthropogenic climate change as an outcome of fossil fuel use. But that extraction doesn't occur in a vacuum - fuels are extracted and burned for heat, for electricity, for transport, for industry.
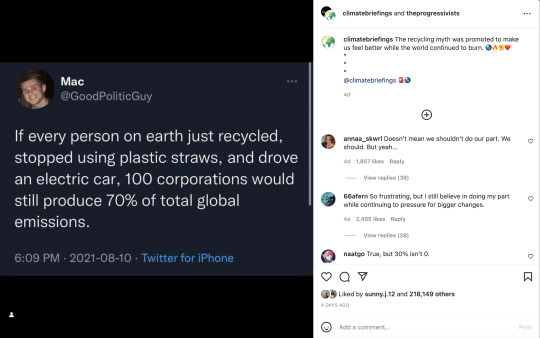
The tweet about nothing changing if people didn't drive and used plastic straws is exactly wrong: fossil fuels are valuable to extract because they're used for everything around us. In the US, transportation accounts for ~29% of greenhouse gas emissions, and 57% of that is from personal vehicles. In 2016, the average passenger car fuel efficiency in the US was 22.1 miles per gallon; an electric car can easily get > 100 miles-per-gallon-equivalent, some as high as 142 miles-per-gallon-equivalent. Magically substituting all gas cars in the US alone for electric would slash nationwide emissions by 13 percentage points even if all those vehicles were powered by electricity made from fossil fuels! (Clearly there are a lot of gross assumptions and approximations there.) (Also, yes, magic wand car swaps aren't a thing we can do in real life, but it's what the tweet said, so I wanted to toss it in there.)
Like, there's a lot of complexity to global emissions - who's responsible, what levers we have to move things in a better direction, what any individual can or can't do. But this specific piece of misinformation or at least misrepresentation really ought to be excised from the record.
#climate change#discourse#global warming#long post#effortpost#slightly more coherent version of the thing I was trying to poke at earlier
25 notes
·
View notes
Text
Data Analysis: Turning Information into Insight
In nowadays’s digital age, statistics has come to be a vital asset for businesses, researchers, governments, and people alike. However, raw facts on its personal holds little value till it's far interpreted and understood. This is wherein records evaluation comes into play. Data analysis is the systematic manner of inspecting, cleansing, remodeling, and modeling facts with the objective of coming across beneficial information, drawing conclusions, and helping selection-making.
What Is Data Analysis In Research

What is Data Analysis?
At its middle, records analysis includes extracting meaningful insights from datasets. These datasets can variety from small and based spreadsheets to large and unstructured facts lakes. The primary aim is to make sense of data to reply questions, resolve issues, or become aware of traits and styles that are not without delay apparent.
Data evaluation is used in truely every enterprise—from healthcare and finance to marketing and education. It enables groups to make proof-based choices, improve operational efficiency, and advantage aggressive advantages.
Types of Data Analysis
There are several kinds of information evaluation, every serving a completely unique purpose:
1. Descriptive Analysis
Descriptive analysis answers the question: “What happened?” It summarizes raw facts into digestible codecs like averages, probabilities, or counts. For instance, a store might analyze last month’s sales to decide which merchandise achieved satisfactory.
2. Diagnostic Analysis
This form of evaluation explores the reasons behind beyond outcomes. It answers: “Why did it occur?” For example, if a agency sees a surprising drop in internet site visitors, diagnostic evaluation can assist pinpoint whether or not it changed into because of a technical problem, adjustments in search engine marketing rating, or competitor movements.
3. Predictive Analysis
Predictive analysis makes use of historical information to forecast destiny consequences. It solutions: “What is probable to occur?” This includes statistical models and system getting to know algorithms to pick out styles and expect destiny trends, such as customer churn or product demand.
4. Prescriptive Analysis
Prescriptive analysis provides recommendations primarily based on facts. It solutions: “What have to we do?” This is the maximum advanced type of analysis and often combines insights from predictive analysis with optimization and simulation techniques to manual selection-making.
The Data Analysis Process
The technique of information analysis commonly follows those steps:
1. Define the Objective
Before diving into statistics, it’s essential to without a doubt recognize the question or trouble at hand. A well-defined goal guides the entire analysis and ensures that efforts are aligned with the preferred outcome.
2. Collect Data
Data can come from numerous sources which includes databases, surveys, sensors, APIs, or social media. It’s important to make certain that the records is relevant, timely, and of sufficient high-quality.
3. Clean and Prepare Data
Raw information is regularly messy—it may comprise missing values, duplicates, inconsistencies, or mistakes. Data cleansing involves addressing these problems. Preparation may include formatting, normalization, or growing new variables.
Four. Analyze the Data
Tools like Excel, SQL, Python, R, or specialized software consisting of Tableau, Power BI, and SAS are typically used.
5. Interpret Results
Analysis isn't pretty much numbers; it’s about meaning. Interpreting effects involves drawing conclusions, explaining findings, and linking insights lower back to the authentic goal.
6. Communicate Findings
Insights have to be communicated effectively to stakeholders. Visualization tools including charts, graphs, dashboards, and reports play a vital position in telling the story behind the statistics.
7. Make Decisions and Take Action
The last aim of statistics analysis is to tell selections. Whether it’s optimizing a advertising marketing campaign, improving customer support, or refining a product, actionable insights flip data into real-global effects.
Tools and Technologies for Data Analysis
A big selection of gear is available for facts analysis, each suited to distinct tasks and talent levels:
Excel: Great for small datasets and short analysis. Offers capabilities, pivot tables, and charts.
Python: Powerful for complicated facts manipulation and modeling. Popular libraries consist of Pandas, NumPy, Matplotlib, and Scikit-learn.
R: A statistical programming language extensively used for statistical analysis and statistics visualization.
SQL: Essential for querying and handling information saved in relational databases.
Tableau & Power BI: User-friendly enterprise intelligence equipment that flip facts into interactive visualizations and dashboards.
Healthcare: Analyzing affected person statistics to enhance treatment plans, predict outbreaks, and control resources.
Finance: Detecting fraud, coping with threat, and guiding investment techniques.
Retail: Personalizing advertising campaigns, managing inventory, and optimizing pricing.
Sports: Enhancing performance through participant records and game analysis.
Public Policy: Informing choices on schooling, transportation, and financial improvement.
Challenges in Data Analysis
Data Quality: Incomplete, old, or incorrect information can lead to deceptive conclusions.
Data Privacy: Handling sensitive records requires strict adherence to privacy guidelines like GDPR.
Skill Gaps: There's a developing demand for skilled information analysts who can interpret complicated facts sets.
Integration: Combining facts from disparate resources may be technically hard.
Bias and Misinterpretation: Poorly designed analysis can introduce bias or lead to wrong assumptions.
The Future of Data Analysis
As facts keeps to grow exponentially, the sector of facts analysis is evolving rapidly. Emerging developments include:
Artificial Intelligence (AI) & Machine Learning: Automating evaluation and producing predictive fashions at scale.
Real-Time Analytics: Enabling decisions based totally on live data streams for faster reaction.
Data Democratization: Making records handy and understandable to everybody in an business enterprise
2 notes
·
View notes
Text
Why Tableau is Essential in Data Science: Transforming Raw Data into Insights

Data science is all about turning raw data into valuable insights. But numbers and statistics alone don’t tell the full story—they need to be visualized to make sense. That’s where Tableau comes in.
Tableau is a powerful tool that helps data scientists, analysts, and businesses see and understand data better. It simplifies complex datasets, making them interactive and easy to interpret. But with so many tools available, why is Tableau a must-have for data science? Let’s explore.
1. The Importance of Data Visualization in Data Science
Imagine you’re working with millions of data points from customer purchases, social media interactions, or financial transactions. Analyzing raw numbers manually would be overwhelming.
That’s why visualization is crucial in data science:
Identifies trends and patterns – Instead of sifting through spreadsheets, you can quickly spot trends in a visual format.
Makes complex data understandable – Graphs, heatmaps, and dashboards simplify the interpretation of large datasets.
Enhances decision-making – Stakeholders can easily grasp insights and make data-driven decisions faster.
Saves time and effort – Instead of writing lengthy reports, an interactive dashboard tells the story in seconds.
Without tools like Tableau, data science would be limited to experts who can code and run statistical models. With Tableau, insights become accessible to everyone—from data scientists to business executives.
2. Why Tableau Stands Out in Data Science
A. User-Friendly and Requires No Coding
One of the biggest advantages of Tableau is its drag-and-drop interface. Unlike Python or R, which require programming skills, Tableau allows users to create visualizations without writing a single line of code.
Even if you’re a beginner, you can:
✅ Upload data from multiple sources
✅ Create interactive dashboards in minutes
✅ Share insights with teams easily
This no-code approach makes Tableau ideal for both technical and non-technical professionals in data science.
B. Handles Large Datasets Efficiently
Data scientists often work with massive datasets—whether it’s financial transactions, customer behavior, or healthcare records. Traditional tools like Excel struggle with large volumes of data.
Tableau, on the other hand:
Can process millions of rows without slowing down
Optimizes performance using advanced data engine technology
Supports real-time data streaming for up-to-date analysis
This makes it a go-to tool for businesses that need fast, data-driven insights.
C. Connects with Multiple Data Sources
A major challenge in data science is bringing together data from different platforms. Tableau seamlessly integrates with a variety of sources, including:
Databases: MySQL, PostgreSQL, Microsoft SQL Server
Cloud platforms: AWS, Google BigQuery, Snowflake
Spreadsheets and APIs: Excel, Google Sheets, web-based data sources
This flexibility allows data scientists to combine datasets from multiple sources without needing complex SQL queries or scripts.
D. Real-Time Data Analysis
Industries like finance, healthcare, and e-commerce rely on real-time data to make quick decisions. Tableau’s live data connection allows users to:
Track stock market trends as they happen
Monitor website traffic and customer interactions in real time
Detect fraudulent transactions instantly
Instead of waiting for reports to be generated manually, Tableau delivers insights as events unfold.
E. Advanced Analytics Without Complexity
While Tableau is known for its visualizations, it also supports advanced analytics. You can:
Forecast trends based on historical data
Perform clustering and segmentation to identify patterns
Integrate with Python and R for machine learning and predictive modeling
This means data scientists can combine deep analytics with intuitive visualization, making Tableau a versatile tool.
3. How Tableau Helps Data Scientists in Real Life
Tableau has been adopted by the majority of industries to make data science more impactful and accessible. This is applied in the following real-life scenarios:
A. Analytics for Health Care
Tableau is deployed by hospitals and research institutions for the following purposes:
Monitor patient recovery rates and predict outbreaks of diseases
Analyze hospital occupancy and resource allocation
Identify trends in patient demographics and treatment results
B. Finance and Banking
Banks and investment firms rely on Tableau for the following purposes:
✅ Detect fraud by analyzing transaction patterns
✅ Track stock market fluctuations and make informed investment decisions
✅ Assess credit risk and loan performance
C. Marketing and Customer Insights
Companies use Tableau to:
✅ Track customer buying behavior and personalize recommendations
✅ Analyze social media engagement and campaign effectiveness
✅ Optimize ad spend by identifying high-performing channels
D. Retail and Supply Chain Management
Retailers leverage Tableau to:
✅ Forecast product demand and adjust inventory levels
✅ Identify regional sales trends and adjust marketing strategies
✅ Optimize supply chain logistics and reduce delivery delays
These applications show why Tableau is a must-have for data-driven decision-making.
4. Tableau vs. Other Data Visualization Tools
There are many visualization tools available, but Tableau consistently ranks as one of the best. Here’s why:
Tableau vs. Excel – Excel struggles with big data and lacks interactivity; Tableau handles large datasets effortlessly.
Tableau vs. Power BI – Power BI is great for Microsoft users, but Tableau offers more flexibility across different data sources.
Tableau vs. Python (Matplotlib, Seaborn) – Python libraries require coding skills, while Tableau simplifies visualization for all users.
This makes Tableau the go-to tool for both beginners and experienced professionals in data science.
5. Conclusion
Tableau has become an essential tool in data science because it simplifies data visualization, handles large datasets, and integrates seamlessly with various data sources. It enables professionals to analyze, interpret, and present data interactively, making insights accessible to everyone—from data scientists to business leaders.
If you’re looking to build a strong foundation in data science, learning Tableau is a smart career move. Many data science courses now include Tableau as a key skill, as companies increasingly demand professionals who can transform raw data into meaningful insights.
In a world where data is the driving force behind decision-making, Tableau ensures that the insights you uncover are not just accurate—but also clear, impactful, and easy to act upon.
#data science course#top data science course online#top data science institute online#artificial intelligence course#deepseek#tableau
3 notes
·
View notes
Text
Unlock the Power of Data Analysis with STAT Data Modeling Software - LabDeck's Stat Studio
In today's data-driven world, having the right tools to analyze and interpret vast amounts of data is essential for researchers, data scientists, and analysts. LabDeck’s Stat Studio stands out as a premier STAT Data Modeling Software, designed to meet the diverse needs of professionals who work with complex datasets. This robust software offers an intuitive interface combined with powerful analytical features, enabling users to perform advanced statistical modeling with ease.
Why Choose Stat Studio for Your Data Analysis Needs?
Stat Studio is more than just another statistical software; it's an all-in-one solution that helps you unlock deeper insights from your data. Here's why it's a top choice for anyone looking to elevate their data modeling capabilities:
1. Advanced Regression Analysis
One of Stat Studio's most powerful features is its regression analysis toolset. Whether you are performing basic linear regression or more complex methods, Stat Studio gives you the flexibility to choose the right model for your data. Key statistical measures, such as Mean Squared Error (MSE) and R-squared values, are automatically calculated and displayed, providing instant insight into your model's performance. This makes it easy to interpret relationships between variables, ensuring accurate and reliable results.
2. Comprehensive Data Handling
Stat Studio excels in data handling by supporting a wide range of file formats and data sources. With its flexible import options, users can seamlessly integrate and analyze datasets from various origins. Whether your data comes from spreadsheets, databases, or other statistical software, Stat Studio ensures that you can work with it efficiently.
3. Customizable Visualizations
Data visualization is an integral part of any analysis, and Stat Studio’s advanced plotting capabilities make it simple to create professional-grade charts and graphs. Users can easily generate scatter plots, line graphs, bar charts, and more, with a full range of customizable options like marker styles, line types, and color schemes. Additionally, the software allows you to overlay regression lines and add trend lines, giving your visualizations deeper analytical value.
4. Tailored Analysis and Presentation
Customization doesn’t end with visuals. Stat Studio offers extensive options to tailor every aspect of your analysis to meet specific presentation or publication requirements. You can adjust parameters for data scaling, clean your datasets, and fine-tune the presentation of your results to suit your audience, whether you are presenting to a boardroom or preparing for publication.
Advanced Features for Complex Analyses
For users who require more than just basic analysis, Stat Studio offers an array of advanced features. A dedicated “Tests” tab hints at the software’s ability to run a wide variety of statistical tests, including hypothesis testing, ANOVA, and more. These features make Stat Studio a versatile tool for users in fields like academia, market research, healthcare, and beyond.
Additionally, the software includes tools for data cleaning and scaling, which are essential for preparing large and complex datasets for accurate analysis. These pre-processing steps ensure that your data is ready for in-depth statistical modeling, leading to more reliable and meaningful results.
Conclusion: Empower Your Data with LabDeck's Stat Studio
LabDeck’s Stat Studio offers a complete package for anyone looking to perform STAT Data Modeling software. With its combination of advanced analysis features, flexible data handling, and customizable visualization options, Stat Studio is a powerful tool for both novice and experienced statisticians alike. Whether you're conducting regression analysis, creating intricate data visualizations, or preparing your data for publication, Stat Studio provides the precision, efficiency, and versatility you need to succeed.
To learn more about how Stat Studio can revolutionize your data analysis process, visit the official page here.
Embrace the power of Stat Studio and take your data modeling to new heights!
2 notes
·
View notes
Note
Can i have advanced spiritual knowledge
Yes, but the real meaning of "pythagorean silence" (in the sense of the magus' four duties -- to know, to will, to dare, and to be silent) is that even a mighty stream cannot penetrate a watertight dam; either life initiates you or you remain uninitated, & as they say, "if you gotta ask you're never gonna know".
That said, here's a little:
Language is a human symbiote -- an immaterial nonhuman intelligence with which we have allied our entire species, in exchange for superpowers denied to other hominids (impossibly long and exact memories, which can be transmitted fairly reliably between individuals, and -- after writing -- can even be transmitted across long spans of space and time). What does Language get? It gets to live rooted inside us. It's a kind of vine, rooted in our brains, connecting us out in another dimension.
It is, crucially, not from outer space -- no matter what Burroughs may think. It is, however, the intelligence or intelligences we contact when we have a "UFO abduction" experience (or a "demonic possession" or "ghostly encounter" or "visitation from the blessed virgin" or "sasquatch sighting").
The form of language is a massive distributed graph database. Every human contains a set of partially-overlapping sign-signifier-cooccurrence-probability matrices with fuzzy history / context hints. This is the verbal mind. Through conversation, and through contact with the real world, the weights (usually) approach homeostasis. The system is complex, so "the market can remain distorted for longer than you can remain solvent" (Keynes).
There is also another element -- a trickster principle. It may be inside of Language, or it may be fighting against Language, or the two may actually be the same thing. The trickster element deterritorializes: the edges of what was some category X will be eaten away, creating a larger region for what was previously X, but at the same time redefining what X means. The trickster element loves to tie knots, and poke holes.
We all, collectively, constitute the landscape upon which this ecosystem grows. Or, Humanity is the organism that is infected by this virus (which has its fingers in every individual Human, but is unimaginable from the perspective of a human scale).
The magus, even if he does not work with entities (they are tricksters themselves), is making a demonic alliance with Language, the great other. The magus is a minor earthquake, the acidity of the soil in a particular spot, shit and water, a bit of pruning and weeding in a raised bed. The whole ecosystem can thus be influenced.
Therefore, magick does not depend upon any supernatural (or unknown) forces -- only a hypernatural application of the ultimate implications of known and accepted tendencies, in aggregate when looked at from above as a complete system.
7 notes
·
View notes
Text
Data mining

1.What's Data mining ?
Datamining is the process of extracting and discovering patterns in large datasets involving methods at the intersection of machine learning, statistics and database systems. Datamining is interdisciplinary subfield of computer-science and statistics with overall goal of extracting information (with intelliegent methods) from a data set and transforming the information into a comprensible structure for further use. Data mining is the analysis step of The KDD process "Knowledge discovery in database".
2.What's KDD process ?
KDD process is known as "Knowledge Discovery in Database".It"s a multi-step process of finding knowledge from large data sets and emphasizes the high-level application of particular datamining methods.It's of interests to researchers in machine learning, pattern recognition, databases, ststistics, artificial intelligence, knowledge aquisition for experts systems and data-visualization. The picture below defines the different steps of KDD process and each of those steps have an input and output entity. The KDD process can't be executed without beginning on data.

3.What are the different steps of the KDD process ?
The overall process of finding and interpretting patterns from data involves the repeated application of the following steps mentioned in the graph above :
Selection : we create a target data set by seecting a part of the overall data set as a sample then focusing on a subset of variables on which discovery is to be performed. The result of these step is a subset of data considered as a sample.
Preprocessing : These step of the KDD process takes the target data set as an input then it applyes data cleaning by removing the noise from the input data set then restucturing the data set. The output of these operation is a preprocessed dataset that can be able to be transformed in the next step.
Data transformation : These step takes the preprocessed data as input and tres to find some useful features depending on the goal of the task and reducing dimension to execute an effective learining datamining.
Data mining : in this phase we will descide whether the goal of KDD process is classification, regression, clustering ...etc. Discover the patterns of interests.
Interpretation : Interpretating mined patterns and consolidating discovered knowledge.
4.What are data mining tasks ?
There are several steps that are defined in the sub-process of KDD especially in datamining steps. In Data mining, there are 02 types of data mining that are :
Predictive mining: predective data mining is the analysis done to predict a future event or other data or trends and to predict something will happen in the near future. Predective data mining offers a better future analysis and to make better decisions to add a value in predective analytics like for example predecting the future customer of a defined service, define the future price of oil and gaz in the world market, define the next ill of an international pandemic, define the future political conflict ... etc. There are 4 types of descriptive data mining tasks which are :
Classification analysis : It is used to retrieve critical and pertinent data and metadata. It categorizes information into various groups. Classification Analysis is best demonstrated by email providers. They use algorithms to determine whether or not a message is legitimate.
Regression Analysis : It tries to express the interdependence of variables. Forecasting and prediction are common applications.
Time Serious Analysis : It is a series of well-defined data points taken at regular intervals.
Prediction Analysis : It is related to time series, but the time isn’t restricted.
Descriptive mining : descriptive data mining is to describe data and make data more readable to human beings, it's used to extract information from previous events and data and to discovering an interesting patterns and association behind data. It's also used to exract correlations, relationships between features and finding new laws and regularities based on data. There are four different types of Descriptive Data Mining tasks. They are as follows :
Clustering analysis : It is the process of determining which data sets are similar to one another. For example, to increase conversion rates, clusters of customers with similar buying habits can be grouped together with similar products.
Summerazation analysis : It entails methods for obtaining a concise description of a dataset. For example, summarising a large number of items related to Christmas season sales provides a general description of the data, which can be extremely useful to sales and marketing managers.
Association rules analysis : This method aids in the discovery of interesting relationships between various variables in large databases. The retail industry is the best example. As the holiday season approaches, retail stores stock up on chocolates, with sales increasing before the holiday, which is accomplished through Data Mining.
Sequence discovery analysis : It's all about how to do something in a specefic order. For instance, a user may frequently purchase shaving gel before purchasing razor in a store.It all comes down to the order in which the user purchases the product, and the store owner can then arrange the items accordingly.
5.Links :
3 notes
·
View notes
Text
Python FullStack Developer Jobs

Introduction :
A Python full-stack developer is a professional who has expertise in both front-end and back-end development using Python as their primary programming language. This means they are skilled in building web applications from the user interface to the server-side logic and the database. Here’s some information about Python full-stack developer jobs.
Job Responsibilities:
Front-End Development: Python full-stack developers are responsible for creating and maintaining the user interface of a web application. This involves using front-end technologies like HTML, CSS, JavaScript, and various frameworks like React, Angular, or Vue.js.
Back-End Development: They also work on the server-side of the application, managing databases, handling HTTP requests, and building the application’s logic. Python, along with frameworks like Django, Flask, or Fast API, is commonly used for back-end development.
Database Management: Full-stack developers often work with databases like PostgreSQL, MySQL, or NoSQL databases like MongoDB to store and retrieve data.
API Development: Creating and maintaining APIs for communication between the front-end and back-end systems is a crucial part of the job. RESTful and Graph QL APIs are commonly used.
Testing and Debugging: Full-stack developers are responsible for testing and debugging their code to ensure the application’s functionality and security.
Version Control: Using version control systems like Git to track changes and collaborate with other developers.
Deployment and DevOps: Deploying web applications on servers, configuring server environments, and implementing continuous integration/continuous deployment (CI/CD) pipelines.
Security: Ensuring the application is secure by implementing best practices and security measures to protect against common vulnerabilities.
Skills and Qualifications:
To excel in a Python full-stack developer role, you should have the following skills and qualifications:
Proficiency in Python programming.
Strong knowledge of front-end technologies (HTML, CSS, JavaScript) and frameworks.
Expertise in back-end development using Python and relevant web frameworks.
Experience with databases and data modeling.
Knowledge of version control systems (e.g., Git).
Familiarity with web servers and deployment.
Understanding of web security and best practices.
Problem-solving and debugging skills.
Collaboration and teamwork.
Continuous learning and staying up to date with the latest technologies and trends.
Job Opportunities:
Python full-stack developers are in demand in various industries, including web development agencies, e-commerce companies, startups, and large enterprises. Job titles you might come across include Full-Stack Developer, Python Developer, Web Developer, or Software Engineer.
The job market for Python full-stack developers is generally favorable, and these professionals can expect competitive salaries, particularly with experience and a strong skill set. Many companies appreciate the versatility of full-stack developers who can work on both the front-end and back-end aspects of their web applications.
To find Python full-stack developer job opportunities, you can check job boards, company career pages, and professional networking sites like LinkedIn. Additionally, you can work with recruitment agencies specializing in tech roles or attend tech job fairs and conferences to network with potential employers.
Python full stack developer jobs offer a range of advantages to those who pursue them. Here are some of the key advantages of working as a Python full stack developer:
Versatility: Python is a versatile programming language, and as a full stack developer, you can work on both front-end and back-end development, as well as other aspects of web development. This versatility allows you to work on a wide range of projects and tasks.
High demand: Python is one of the most popular programming languages, and there is a strong demand for Python full stack developers. This high demand leads to ample job opportunities and competitive salaries.
Job security: With the increasing reliance on web and mobile applications, the demand for full stack developers is expected to remain high. This job security provides a sense of stability and long-term career prospects.
Wide skill set: As a full stack developer, you gain expertise in various technologies and frameworks for both front-end and back-end development, including Django, Flask, JavaScript, HTML, CSS, and more. This wide skill set makes you a valuable asset to any development team.
Collaboration: Full stack developers often work closely with both front-end and back-end teams, fostering collaboration and communication within the development process. This can lead to a more holistic understanding of projects and better teamwork.
Problem-solving: Full stack developers often encounter challenges that require them to think critically and solve complex problems. This aspect of the job can be intellectually stimulating and rewarding.
Learning opportunities: The tech industry is constantly evolving, and full stack developers have the opportunity to continually learn and adapt to new technologies and tools. This can be personally fulfilling for those who enjoy ongoing learning.
Competitive salaries: Python full stack developers are typically well-compensated due to their valuable skills and the high demand for their expertise. Salaries can vary based on experience, location, and the specific organization.
Entrepreneurial opportunities: With the knowledge and skills gained as a full stack developer, you can also consider creating your own web-based projects or startup ventures. Python’s ease of use and strong community support can be particularly beneficial in entrepreneurial endeavors.
Remote work options: Many organizations offer remote work opportunities for full stack developers, allowing for greater flexibility in terms of where you work. This can be especially appealing to those who prefer a remote or freelance lifestyle.
Open-source community: Python has a vibrant and active open-source community, which means you can easily access a wealth of libraries, frameworks, and resources to enhance your development projects.
Career growth: As you gain experience and expertise, you can advance in your career and explore specialized roles or leadership positions within development teams or organizations.

Conclusion:
Python full stack developer jobs offer a combination of technical skills, career stability, and a range of opportunities in the tech industry. If you enjoy working on both front-end and back-end aspects of web development and solving complex problems, this career path can be a rewarding choice.
Thanks for reading, hopefully you like the article if you want to take Full stack master's course from our Institute, please attend our live demo sessions or contact us: +918464844555 providing you with the best Online Full Stack Developer Course in Hyderabad with an affordable course fee structure.
2 notes
·
View notes